
Die Art und Weise, wie wir Unternehmensdaten analysieren und kommunizieren, steht vor einem fundamentalen Wandel. Jahrzehntelang dominierten Business-Intelligence-Tools wie Power BI, Qlik oder Tableau die Reporting-Landschaft. Sie halfen dabei, Daten aufzubereiten, in Dashboards zu visualisieren und über vordefinierte KPIs greifbar zu machen. Doch mit dem Aufstieg von Künstlicher Intelligenz und Large Language Models (LLMs) wie GPT beginnt eine neue Ära: Statt Dashboards zu durchforsten, stellen Nutzer einfach ihre Fragen – und erhalten kontextbasierte, direkte Antworten.
Dieser Blogpost beleuchtet, warum Prompt und Context Engineering das Reporting revolutionieren – und was das für Analysten, Entscheider und Datenplattformen bedeutet und neue Reporting-Kulturen einleiten wird.
Status Quo: Wie klassisches Reporting heute funktioniert
Im klassischen Reporting steht die Visualisierung im Mittelpunkt. Unternehmen investieren viel Zeit und Ressourcen in den Aufbau von Dashboards, Datenmodellen und vordefinierten Reports. Business Intelligence Tools wie Power BI, Tableau oder QlikSense ermöglichen es Fachanwendern, über Drag-and-Drop, Filterfunktionen und Interaktionen Daten eigenständig zu erkunden – das Prinzip des Self-Service-Reportings hat sich etabliert.

In der Theorie klingt das vielversprechend: Fachabteilungen sollen unabhängig vom zentralen Controlling Erkenntnisse aus Daten gewinnen können, datengetriebene Entscheidungen werden zum Zielbild. Doch in der Praxis zeigt sich: Die Realität ist komplexer – und das klassische Reporting wird zunehmend von vier hartnäckigen Schattengeistern heimgesucht, die tief im Reporting-Alltag verankert sind.
🔴 Der rote Geist: Excel-Wildwuchs
Der erste dieser Geister ist der 🔴 rote Geist des Excel-Wildwuchses. Trotz moderner BI-Systeme blühen vielerorts weiterhin lokale Excel-Insellösungen. Ein Vertriebscontroller erstellt beispielsweise monatlich eine Absatzstatistik auf Basis einer lokal gespeicherten Excel-Datei, die er händisch aus SAP exportiert. Zwischen Makros, S-Verweisen und manuellem Copy-Paste schleichen sich Datenfehler ein – und am Ende unterscheidet sich der Bericht vom offiziellen Power-BI-Dashboard des Controllings. Niemand weiß, welcher Wert korrekt ist. Solche parallelen Strukturen untergraben die Glaubwürdigkeit der Zahlenbasis und erschweren jede Diskussion.
🔵 Der blaue Geist: Langsame Reports
Dann wäre da der 🔵 blaue Geist der langsamen Reports, der für unnötige Verzögerungen sorgt. Monatsabschlüsse verzögern sich, weil Datenpipelines nicht automatisiert sind oder Schnittstellen haken. Ein typisches Beispiel: Die Finanzabteilung benötigt eine Übersicht über offene Posten zum Monatsende. Doch bis alle Datenquellen abgestimmt, verarbeitet und in der Reporting-Oberfläche aktualisiert sind, vergehen mehrere Tage. Die Geschäftsleitung trifft Entscheidungen auf Basis von Zahlen, die nicht mehr aktuell sind.
🟢 Der grüne Geist: Daten-Silos
Der 🟢 grüne Geist der Daten-Silos sorgt dafür, dass Daten in abteilungsspezifischen Systemen gefangen bleiben. Marketing nutzt ein CRM, der Vertrieb ein eigenes Dashboard-Tool, das Controlling arbeitet mit SAP – und zwischen den Systemen gibt es keine direkte Verbindung. Eine ganzheitliche Datenanalyse über Kundensegmente, Kampagnenreichweite und Umsatzbeiträge ist kaum möglich, da Datenschnittstellen fehlen und der Integrationsaufwand zu hoch ist.
🟣 Der violette Geist: KPI-Chaos
Schließlich erscheint noch der 🟣 violette Geist des KPI-Chaos, der regelmäßig für Verwirrung in Meetings sorgt. Begriffe wie EBITDA, Deckungsbeitrag oder Conversion Rate sind in vielen Unternehmen uneinheitlich definiert – selbst innerhalb derselben Organisation. So kommt es etwa im Monatsmeeting zu widersprüchlichen Aussagen: Der CFO präsentiert den EBITDA-Wert laut offiziellem Reporting, der Vertriebsleiter bringt einen eigenen Wert ein, der auf abteilungsinternen Definitionen basiert. Die Diskussion driftet schnell ab – nicht über die Aussagekraft der Zahlen, sondern darüber, welcher Begriff eigentlich was bedeutet.
Diese vier Schattengeister machen deutlich: Die Herausforderungen im klassischen Reporting liegen nicht nur in der Technik – sondern in fehlender Standardisierung, inkonsistenter Datenstruktur und mangelnder Kontextualisierung. Wer diese Hürden überwinden will, muss Reporting neu denken – flexibel, kontextbewusst und KI-gestützt.
Treiber der Disruption: KI, LLMs und neue Erwartungen
Die rasante Entwicklung generativer KI verändert nicht nur Technologien – sie verändert auch tiefgreifend die Erwartungshaltung von Führungskräften an den Umgang mit Daten. Managerinnen und Manager, die sich im Alltag längst daran gewöhnt haben, über Systeme wie ChatGPT in Sekundenschnelle verständliche Antworten auf komplexe Fragen zu erhalten, stellen sich zunehmend die Frage: Warum sollte ich mich überhaupt noch durch ein Dashboard klicken – wenn ich auch einfach fragen kann?
Diese neue Erwartungshaltung ist kein technisches Detail – sie ist Ausdruck eines grundlegenden Paradigmenwechsels: In der Welt der Sprachmodelle zählt nicht mehr das Werkzeug, sondern das Ergebnis. Es geht nicht mehr darum, welche Visualisierungstechniken zur Verfügung stehen oder wie viele Filter in einem Dashboard korrekt gesetzt werden – sondern einzig und allein darum, schnell, korrekt und verständlich Antworten auf unternehmerisch relevante Fragen zu erhalten.
Large Language Models wie GPT-4 sind dabei in der Lage, in natürlicher Sprache mit Daten zu interagieren – vorausgesetzt, sie sind technisch korrekt angebunden oder über ein sogenanntes semantisches Modell eingebettet. Damit verschiebt sich der Fokus im Reporting: Nicht mehr die Erstellung eines Reports, sondern die intelligente Interaktion mit Daten rückt in den Mittelpunkt.
In diesem Zusammenhang gewinnt das sogenannte Prompt Engineering an Bedeutung – also die Fähigkeit, präzise, zielführende Fragen an ein KI-System zu stellen. Diese Fähigkeit wird zur neuen Schnittstelle zwischen Mensch und Maschine. Wer sie beherrscht, ist in der Lage, ohne technische Vorkenntnisse komplexe Datenabfragen auszuführen – und das in einer Form, die für Manager:innen intuitiv und alltagstauglich ist.
Die Folge: Klassische Reporting-Architekturen geraten zunehmend ins Wanken. Sie wurden ursprünglich gebaut, um standardisierte Reports zu erzeugen – nicht, um auf spontane Fragen zu reagieren. Doch genau das wird jetzt erwartet: Dialog statt Dashboard, Antwort statt Analysearbeit, Flexibilität statt starrem Standardbericht.
Für moderne Datenplattformen bedeutet das: Sie müssen die Benutzererfahrung ins Zentrum stellen. Die entscheidende Frage ist nicht mehr: Welche Tools haben wir im Einsatz?, sondern: Wie schnell und verständlich bekommen unsere Entscheider die Informationen, die sie wirklich brauchen?
Neue Paradigmen: Vom Dashboard zur Antwort
Die wohl entscheidendste Veränderung im Reporting der letzten Jahre ist ein fundamentaler Perspektivwechsel: Im Zentrum steht nicht mehr die Visualisierung – sondern die Erkenntnis. Klassisches Reporting basierte auf Dashboards, Diagrammen und KPI-Tabellen. Heute dagegen erwarten Nutzer konkrete Antworten auf ihre Fragen – intuitiv, schnell und ohne Umwege.
Ein prägnantes Beispiel:
Statt sich mühsam durch ein Dashboard mit drei Filtern und zwei Diagrammen zu klicken, um die Absatzentwicklung im Q2 zu analysieren, genügt heute eine einfache Frage:
„Warum war der Absatz im Q2 rückläufig?“
Ein KI-gestütztes Reporting-System durchsucht automatisch relevante Datenquellen, berücksichtigt interne KPIs und ggf. auch externe Faktoren (z. B. Marktentwicklungen oder Lieferengpässe) – und liefert eine verständliche, strukturierte Antwort. Oft sogar mit konkreter Begründung und Handlungsempfehlung.
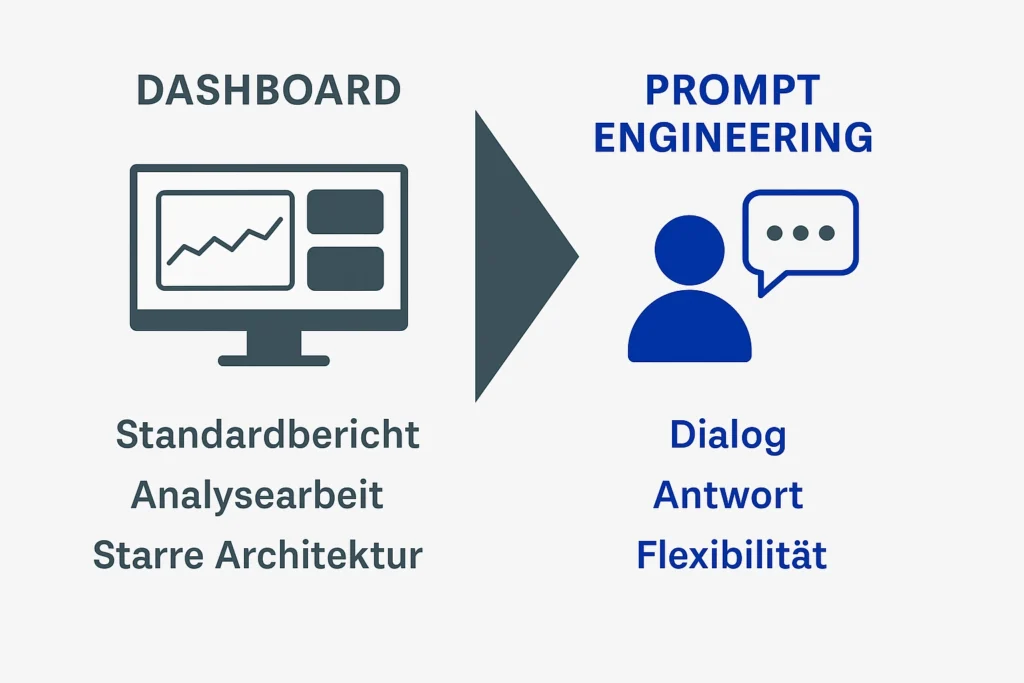
Dieser Wandel ist tiefgreifend: Reporting wird damit dialogorientiert statt statisch. Es verschiebt sich vom Werkzeug zur Konversation mit den Daten. Und das Beste: Es sind keine technischen Kenntnisse mehr erforderlich. Entscheidend ist nicht mehr, wie gut man sich mit Power BI oder Pivot-Tabellen auskennt – sondern, wie präzise man Fragen stellen und den geschäftlichen Kontext erfassen kann.
So wird Business Intelligence zum Business Dialog – flexibel, intuitiv und verständlich. Unternehmen, die diesen Wandel frühzeitig erkennen, verschaffen sich einen echten Wettbewerbsvorteil bei der Nutzung von Daten.
Prompt Engineering für Controller und Analysten
Im modernen, KI-gestützten Reporting kommt es nicht mehr nur darauf an, Zahlen zu lesen oder Diagramme zu erstellen – sondern die richtigen Fragen zu stellen. Genau hier setzt das Konzept des Prompt Engineerings an.

Prompt Engineering bedeutet: Man lernt, einem KI-System wie ChatGPT oder einem unternehmensinternen Sprachmodell gezielte und verständliche Anfragen zu stellen, um klare und verlässliche Antworten zu erhalten. Für Controller, Analysten und Fachabteilungen ist das ein neuer, aber enorm wichtiger Skill.
Denn wer eine Frage wie „Wie sieht der Umsatz aus?“ stellt, bekommt meist nur eine grobe, wenig hilfreiche Antwort. Wird die Frage hingegen präzise formuliert – etwa:
„Vergleiche den Umsatz im zweiten Quartal 2024 mit dem Vorjahresquartal, aufgeschlüsselt nach Region und Produktlinie“,
dann kann die künstliche Intelligenz gezielt auf die Daten zugreifen, sinnvoll analysieren und eine nachvollziehbare Antwort liefern.
Das Schöne daran: Diese Fähigkeit ist trainierbar. Man muss kein Programmierer sein, um gute Prompts zu erstellen – es braucht lediglich ein Verständnis für das eigene Geschäftsmodell, für Datenstrukturen und für klare Fragestellungen.
Für Unternehmen bedeutet das: Wer seine Mitarbeitenden fit machen will für die Zukunft der datenbasierten Entscheidungsfindung, sollte gezielt in Prompt-Kompetenz investieren. Denn in einer Welt, in der Fragen wichtiger werden als Dashboards, ist die Fähigkeit, mit KI-Systemen effektiv zu kommunizieren, ein echter Wettbewerbsvorteil.

Von Prompt zu Context Engineering: Die nächste Evolutionsstufe
Prompt Engineering ist nur die halbe Miete. Um wirklich zuverlässige und konsistente Antworten zu erhalten, braucht es Context Engineering. Dabei geht es darum, den richtigen Rahmen für die KI zu definieren:
- Wer stellt die Frage?
- In welchem fachlichen Kontext?
- Welche Begriffe gelten?
- Welche Datenquelle ist autoritativ?
Beispiel: Der Begriff „Deckungsbeitrag“ kann je nach Unternehmen und Abteilung unterschiedlich definiert sein. Ohne Kontext wird ein LLM bestenfalls raten – oder im schlimmsten Fall falsche Annahmen treffen.

Context Engineering sorgt dafür, dass KI-Systeme mit einer domänenspezifischen Wissensbasis arbeiten. Dazu gehören semantische Datenmodelle, Ontologien, Rollen- und Nutzerinformationen, aber auch Business Glossaries.
Nur durch Context Engineering lassen sich Halluzinationen vermeiden, Antworten standardisieren und die Qualität von KI-basiertem Reporting sichern.
Was ist Context Engineering?
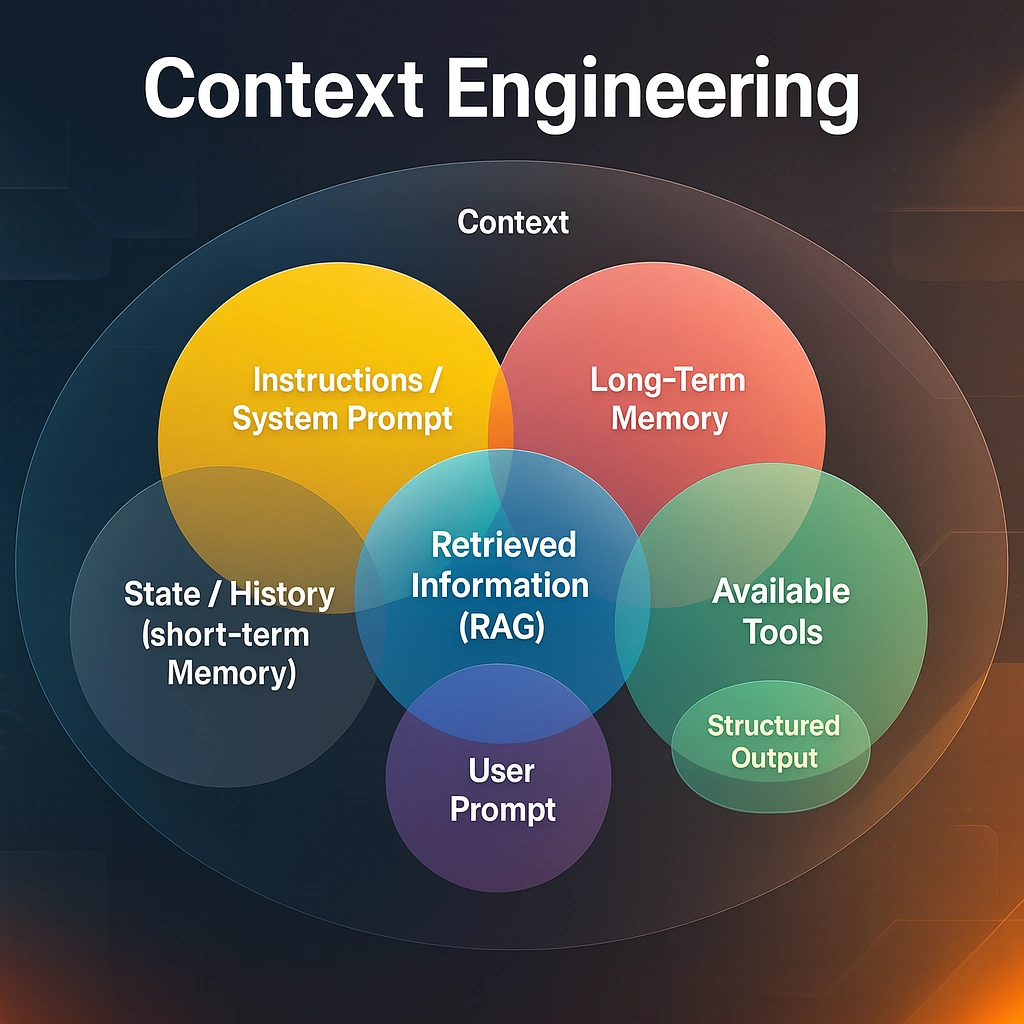
Im Gegensatz zum Prompt Engineering, das sich auf die Gestaltung einzelner Eingabeaufforderungen konzentriert, geht Context Engineering deutlich weiter. Es definiert alle relevanten Informationen, die in das Kontextfenster eines Large Language Models (LLMs) eingespeist werden. Dazu zählen:
- strukturierte Dokumente und Reports
- vergangene Chat-Verläufe oder Interaktionen
- spezifische Beispiele oder Use Cases
- Metadaten zu Nutzerrollen, Abteilungen oder Berechtigungen
- Semantische Datenmodelle, Business Glossaries und Ontologien
Ziel ist es, der Künstlichen Intelligenz (KI) ein domänenspezifisches, verständliches Umfeld bereitzustellen, um präzise, kontextbezogene und vertrauenswürdige Antworten zu generieren.
Du schreibst nicht nur einen Prompt – du gestaltest die gesamte gedankliche Welt, in der das Modell agiert.
Es geht darum, was das Modell sieht (Dokumente, vergangene Chats, Beispiele, Zusammenfassungen), wie es das sieht (strukturiert oder chaotisch) und wann es das sieht (dynamisch eingefügt, statisch, speicherbasiert). Man denkt in Tokens, nicht nur in Anweisungen. System-Prompts. Speicherslots. Tool-Ausgaben. Verlaufskontexte.
Context Engineering endet nicht beim Prompt-Design– es gestaltet die gesamte Unterhaltung.
Warum ist Context Engineering so wichtig?
Nur durch professionelles Context Management lassen sich skalierbare, robuste KI-Systeme aufbauen, die auch in komplexen Geschäftsprozessen zuverlässig funktionieren. Besonders im KI-gestützten Reporting, bei Enterprise-Chatbots oder in intelligenten Assistenzsystemen sorgt Context Engineering dafür, dass:
- Halluzinationen vermieden werden
- Fachbegriffe korrekt interpretiert werden (z. B. „Deckungsbeitrag“ je nach Abteilung)
- Antworten standardisiert, reproduzierbar und compliant sind
- Tokenverbrauch, Latenzzeiten und Kosten im Rahmen bleiben

Was ist der Zweck von Context Engineering?, und die Anwendungsfälle?
Prompt Engineering verfolgt das Ziel, mit einer gezielten Eingabe (Prompt) eine möglichst präzise Antwort vom KI-Modell zu erhalten. Der Fokus liegt dabei auf einmaligen Interaktionen – etwa wenn ein bestimmter Textbaustein, ein Tweet oder ein Code-Snippet erzeugt werden soll. Es geht um punktuelle, kreative oder technische Eingaben, die unmittelbar ein verwertbares Ergebnis liefern sollen.
Die Use Cases zeigen, wie mächtig selbst einfache Prompts sein können – vor allem in kreativen und technischen Bereichen:
- Texterstellung und Copywriting: Ob Werbeanzeige, Social-Media-Post oder Produktbeschreibung – mit dem richtigen Prompt lassen sich in Sekunden verschiedene Varianten generieren, die Zielgruppe, Tonalität und Stil berücksichtigen.
- Inspirierte Tweets: Ein typisches Beispiel: „Schreib mir einen Tweet im Stil von Naval Ravikant“. KI kann bekannte Denk- oder Sprachmuster imitieren und für Content Creation nutzbar machen.
- Code auf Abruf: Entwickler:innen können mit einem einzigen Prompt kleine Programmieraufgaben lösen lassen – zum Beispiel das Erstellen eines Python-Skripts oder einer SQL-Abfrage.
- Überzeugende Demos: Prompt Engineering eignet sich hervorragend für spektakuläre Einzelvorführungen – etwa bei Konferenzen oder in Verkaufsgesprächen, wenn es darum geht, was KI kann.

Context Engineering hingegen hat einen deutlich umfassenderen Zweck: Es soll sicherstellen, dass ein KI-System über längere Zeiträume hinweg, in unterschiedlichen Anwendungsszenarien, mit wechselnden Nutzern und unter chaotischen Bedingungen zuverlässig funktioniert. Hier steht nicht der einzelne Prompt im Vordergrund, sondern das Gesamtbild – also der Aufbau einer robusten, kontextsensiblen Umgebung, in der das Modell kontinuierlich gute Leistungen erbringen kann.
Es ermöglicht stabilere und skalierbare Systeme – gerade für den produktiven Einsatz.
- LLM-Agenten mit Gedächtnis: Komplexe KI-Agenten können auf vergangene Informationen zurückgreifen und langfristige Aufgaben bearbeiten – etwa als persönliche Assistenten oder automatisierte Recherche-Bots.
- Zuverlässige Kunden-Support-Bots: KI-Systeme, die auf validierte Wissensdatenbanken zugreifen und aktuelle Kundenkontexte kennen, reduzieren Halluzinationen und verbessern den Kundenservice nachhaltig.
- Mehrstufige Dialogsysteme: Im Gegensatz zu einfachen Chatbots ermöglichen context-engineerte Modelle mehrstufige Konversationen – ideal für Beratungsprozesse, Onboarding-Flows oder komplexe FAQ-Systeme.
- Produktivitätsorientierte Systeme: In der Produktion zählt Verlässlichkeit. Context Engineering stellt sicher, dass die KI in jedem Durchlauf die richtigen Informationen hat – konsistent, nachvollziehbar und auditierbar.
Ob Kundenservice-Bots, mehrstufige Dialogsysteme oder KI-Agenten mit Gedächtnis – Context Engineering ist die Basis für skalierbare und konsistente KI-Anwendungen in der Praxis.
Warum guter Kontext wichtiger ist als ein einzelner Prompt
In modernen KI-Systemen reicht es nicht mehr aus, einfach nur einen gut formulierten Prompt zu übergeben. Viel entscheidender ist der Kontext, in dem dieser Prompt verarbeitet wird. Genau hier setzt Context Engineering an – es schafft die Umgebung, in der ein Prompt überhaupt sinnvoll verstanden werden kann.
Man kann sich das so vorstellen:
Prompt Engineering konzentriert sich darauf, was man dem Modell in einem bestimmten Moment sagt. Es geht also um die konkrete Anweisung, die man gibt – präzise, fokussiert, aber oft einmalig.
Context Engineering hingegen geht tiefer. Es bezieht sich auf das Wissen, das dem Modell bereits zur Verfügung steht, wenn der Prompt verarbeitet wird. Das können frühere Konversationen, Hintergrundinformationen, System-Prompts oder eingebettete Dokumente sein. All das formt den Rahmen, in dem die KI denkt.
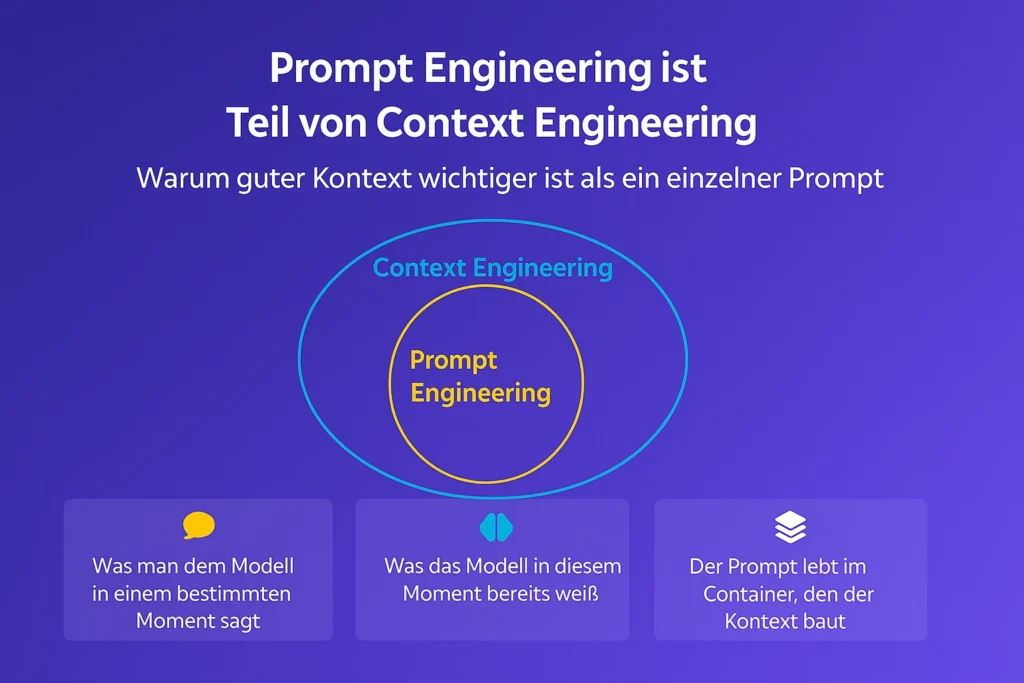
Prompt Engineering ist ein Teilbereich von Context Engineering – nicht umgekehrt.
Ein treffendes Bild:
Der Prompt lebt im Container, den der Kontext baut.
Ohne diesen Container wäre der Prompt wie ein Satz ohne Zusammenhang – im besten Fall geraten, im schlimmsten Fall falsch interpretiert.
Daher gilt: Wer ein zuverlässiges, konsistentes KI-System aufbauen möchte, kommt an Context Engineering nicht vorbei. Es sorgt dafür, dass Prompts nicht nur verstanden, sondern auch im richtigen Zusammenhang interpretiert und beantwortet werden.
Prompt Engineering ist das, was du innerhalb des Kontextfensters tust.
Context Engineering entscheidet, was dieses Fenster füllt.
Man kann den perfekten Prompt entwerfen – aber wenn er hinter 4.000 Tokens irrelevanter Chatverläufe oder schlecht strukturierter Dokumente untergeht? Dann war’s das.
Deshalb gilt: Prompt Engineering bleibt wichtig.
Aber es bewegt sich immer innerhalb des Rahmens, den das Context Engineering vorgibt.
Was passiert, wenn es schief läuft?
Künstliche Intelligenz ist nur so gut wie ihr Input – und das bedeutet: Wer Prompt und Context Engineering unsauber betreibt, riskiert nicht nur unbrauchbare Ergebnisse, sondern auch den Verlust von Zeit, Vertrauen und Skalierbarkeit.
Typische Folgen von schlechtem Prompt Engineering:
- Der Tonfall passt nicht: Die Ausgabe klingt zu technisch, zu flapsig oder schlicht falsch für die Zielgruppe.
- Anweisungen werden ignoriert: Trotz klarer Vorgaben macht das Modell einfach etwas anderes.
- Die KI wirkt „verwirrt“: Man hat das Gefühl, als sei das Modell „betrunken“ – Antworten sind inkonsistent oder zusammenhangslos.
- Stundenlange Optimierung: Man verbringst zu viel Zeit damit, Kommas zu setzen, Formulierungen umzuschreiben und mit Synonymen zu experimentieren – ohne echten Fortschritt.
Typische Folgen von schlechtem Context Engineering:
- Das Modell weiß nicht, warum es überhaupt da ist: Es verliert den Gesprächszusammenhang, vergisst Rollen und Ziele.
- Der Prompt wird überlagert: Wichtige Anweisungen gehen im Rauschen von Chat-Historien oder schlecht strukturierten Dokumenten unter.
- Das Ergebnis ist generisch oder daneben: Die Ausgabe ist entweder oberflächlich oder schlicht falsch – teilweise sogar irreführend.
- Technisches Versagen: RAG-Systeme (Retrieval-Augmented Generation) funktionieren nicht richtig, Speicher-Kontexte (Memory) gehen verloren, Tool-Chaining bricht zusammen.
Wie Context Engineering das Prompt Engineering unterstützt
Context Engineering schafft den Rahmen, in dem Prompt Engineering überhaupt erst wirksam wird. Es sorgt dafür, dass die richtigen Informationen zur richtigen Zeit am richtigen Ort im Kontextfenster der KI verfügbar sind. So wird aus einem einfachen Prompt ein mächtiges Werkzeug.
Einige Beispiele, wie Context Engineering das Prompt Engineering verbessert:
- Relevante Dokumente bereitstellen: Wenn die KI Zugriff auf gut strukturierte Wissensquellen hat, muss der Prompt nicht alles erklären – die Antwort wird fundierter und präziser.
- Rollen und Zieldefinition klären: Ob CEO, Entwickler oder Kundendienst – mit klarer Rollenbeschreibung kann der Prompt spezifischer und zielgerichteter formuliert werden.
- Langzeitgedächtnis aktivieren: Durch Memory-Systeme bleibt der Kontext über mehrere Interaktionen hinweg erhalten – das spart Erklärungen und verbessert die Konsistenz.
- Prompt-Elemente intelligent kombinieren: Gute Kontextarchitektur ermöglicht den Einsatz von modularen Prompts, Retrieval-Mechanismen und Tool-Chaining – das erweitert die Wirkung jedes einzelnen Prompts.

Ein gutes Prompt allein reicht nicht. Selbst die beste Anweisung bringt nichts, wenn sie im Kontextfenster verloren geht – zum Beispiel hinter 12.000 Tokens voller FAQ-Texte und schwer lesbarem JSON-Code. Context Engineering schützt deinen Prompt, indem es sicherstellt, dass er sichtbar, verständlich und priorisiert bleibt.
Doch das ist erst der Anfang. Context Engineering strukturiert alles rund um den Prompt: Speicher (Memory), externe Daten (Retrieval) und der System Prompt werden gezielt eingesetzt, um die Klarheit und Wirksamkeit deiner Anfrage zu sichern. Alles dient einem Ziel – die bestmögliche Antwort auf deinen Prompt zu erhalten.
Ein weiterer Vorteil: Context Engineering macht dein System skalierbar. Man musst nicht für jede Nutzergruppe oder Aufgabe einen neuen Prompt basteln. Stattdessen baut man einen strukturierten Kontext auf, der sich dynamisch an unterschiedliche Situationen anpasst – effizient, wiederverwendbar und robust.
Und schließlich: Context Engineering managt die Einschränkungen. Ob Token-Limit, Antwortgeschwindigkeit oder Kosten – es entscheidet, welche Informationen wirklich wichtig sind und was zur Not weggelassen werden kann, ohne die Antwortqualität zu gefährden.
Weitere Vergleichsfaktoren: Prompt vs. Context Engineering
Der Unterschied zwischen Prompt und Context Engineering zeigt sich nicht nur im „Was“, sondern vor allem im „Wie“ – in Denkweise, Anwendung und Skalierung:
- Mindset:Prompt Engineering denkt in klaren Anweisungen. Context Engineering denkt in Abläufen, Architektur und Kontextsteuerung.
- Anwendungsbereich: Prompt Engineering wirkt innerhalb einer einzelnen Eingabe-Antwort-Interaktion. Context Engineering gestaltet alles, was das Modell sieht: Speicher, Tools, Historie, System-Prompts.
- Wiederholbarkeit: Prompt Engineering ist oft trial-and-error. Context Engineering setzt auf Konsistenz und Wiederverwendbarkeit – über viele Nutzer und Szenarien hinweg.
- Skalierbarkeit: Einzelprompts stoßen bei wachsender Nutzerzahl schnell an ihre Grenzen. Context Engineering ist von Beginn an auf Skalierung ausgelegt.
- Präzision: Während beim Prompt Engineering jedes Wort zählt, sorgt Context Engineering dafür, dass die richtigen Informationen zur richtigen Zeit vorliegen – und entlastet damit den Prompt.
- Fehlersuche: Prompt Engineering bedeutet oft: Formulierung raten. Bei Context Engineering analysiert man das gesamte Kontextfenster, Memory-Slots und Tokenfluss.
- Technischer Aufwand: Prompt Engineering braucht oft nur ein Texteingabefeld. Context Engineering erfordert Memory-Management, RAG-Systeme, API-Chaining und Backend-Logik.
- Risiko bei Fehlern:
Scheitert Prompt Engineering, ist die Antwort vielleicht unpassend. Scheitert Context Engineering, gerät das ganze System aus dem Gleichgewicht – Ziele werden vergessen, Tools falsch eingesetzt. - Zeithorizont: Prompt Engineering eignet sich für einmalige Aufgaben. Context Engineering ermöglicht langfristige, zustandsbehaftete Prozesse und komplexe Dialoge.
- Kompetenztyp: Prompt Engineering ist wie Texten oder kreatives Schreiben. Context Engineering gleicht Systemdesign und Architekturentwicklung für LLMs.
Was das für BI-Tools und Datenplattformen bedeutet
Die Frage liegt nahe: Steht das klassische BI-Tool vor dem Aus? Müssen Power BI, Tableau oder Qlik jetzt um ihre Relevanz fürchten? Die Antwort lautet: Nein – aber ihre Rolle verändert sich grundlegend.
BI-Werkzeuge, die bisher als zentrales Frontend für Datenanalysen galten, entwickeln sich zunehmend zu semantischen Plattformen im Hintergrund. Sie liefern weiterhin die Struktur, Governance und Qualität, die Unternehmen für vertrauenswürdige Analysen benötigen – treten aber visuell zunehmend in den Hintergrund.
Power BI ist ein gutes Beispiel:
Schon heute integriert Microsoft KI-Copiloten, die direkt auf das semantische Modell zugreifen und natürliche Sprache verstehen. Das klassische Dashboard ist damit nicht verschwunden – aber es wird zum Nebenprodukt einer kontextgesteuerten Konversation, nicht zum Startpunkt der Analyse. Statt zu klicken und zu filtern, stellt der Nutzer einfach eine Frage.
Auch moderne Datenplattformen wie Snowflake, Databricks oder SAP Data Sphere folgen diesem Trend. Sie bauen gezielt Funktionen aus, um KI-Systeme über semantische Schichten und APIs anzubinden. Kontextsteuerung, Abfrageoptimierung und rollenbasierte Sicherheit rücken dabei in den Fokus.
Das Reporting wird dadurch nicht abgeschafft, sondern transformiert – vom statischen Bericht zur dialogfähigen Schnittstelle im datengetriebenen Ökosystem. Es entsteht ein neues Zusammenspiel aus Daten, semantischer Logik und generativer KI.
Reporting neu denken – bevor es andere für uns tun
Die Disruption im Reporting ist keine Technologiefrage – sie ist eine Frage der Denkweise. Wer Reporting heute noch als das Bauen und Verteilen von Dashboards versteht, wird von der zukünftigen Entwicklung überholt.
Prompt Engineering und Context Engineering sind dabei keine Spielereien – sondern die neuen Schlüsselkompetenzen in der datengetriebenen Organisation. Sie helfen uns, Information in Bedeutung zu verwandeln, Komplexität zu reduzieren und Technologie in echte Produktivität zu übersetzen.
In Zukunft geht es um Antworten, nicht um Oberflächen. Um Dialoge, nicht um Diagramme. Um Kontext, nicht nur um Zahlen. Prompt und Context Engineering werden zur Schlüsselkompetenz für alle, die mit Daten arbeiten.

Für Unternehmen bedeutet das: Jetzt ist der Zeitpunkt, Reporting neu zu denken – bevor die Fragen gestellt werden, auf die das alte System keine Antwort mehr weiß. Wer sich heute auf diese Entwicklung einlässt, profitiert langfristig von spürbaren Vorteilen in Effizienz, Erkenntnisgewinn und Wettbewerbsfähigkeit.
Zusammenfassend lässt sich festhalten, dass:
man schneller von der Frage zur Erkenntnis kommen wird
Einer der größten Vorteile: Zeitgewinn. In klassischen BI-Umgebungen müssen Nutzer:innen oft manuell durch Filter, Visualisierungen und Tabellen navigieren, um Antworten zu erhalten. Mit KI-gestützten Systemen genügt eine gezielte Frage in natürlicher Sprache – und die Antwort folgt in Sekundenschnelle, präzise und kontextbezogen. Das steigert nicht nur die Effizienz, sondern senkt auch die Einstiegshürden für weniger datenaffine Anwender:innen.
man Intelligente Automatisierung durch Kontext kuratiert
Dank Context Engineering können moderne Reporting-Systeme erkennen, was der Nutzer wirklich wissen will. Sie greifen auf relevante Datenquellen, Geschäftslogiken und Rolleninformationen zu und vermeiden Missverständnisse oder widersprüchliche Ergebnisse. Der Vorteil: höhere Qualität, geringerer manueller Aufwand und mehr Vertrauen in die Analyseergebnisse.
man ein bessere Integration hat – weniger Datensilos besitzt
In vielen Unternehmen sind Informationen fragmentiert über verschiedene Systeme verteilt. Durch den Einsatz semantischer Datenmodelle und offener Schnittstellen (APIs) lassen sich diese Silos auflösen. Das neue Reporting wird zu einer integrierten Wissensplattform, in der Daten, Logiken und Antworten aus verschiedenen Quellen zusammenfließen – nutzbar für alle.
man eine höhere Skalierbarkeit und Wiederverwendbarkeit bekommt
Dashboards für jeden Anwendungsfall manuell zu bauen, ist auf Dauer nicht skalierbar. Moderne Reporting-Architekturen ermöglichen die Wiederverwendung von Kontextbausteinen – etwa definierte Begriffe, Rollen, Regeln oder Prompts. So entsteht ein modulares, skalierbares System, das sich schnell an neue Anforderungen und Nutzergruppen anpassen lässt.
Governance, Kontrolle und Vertrauen
Auch wenn Antworten künftig dialogisch erzeugt werden, bleibt die Datenhoheit beim Unternehmen. Context Engineering ermöglicht die gezielte Steuerung, welche Informationen verfügbar sind, wer was fragen darf und wie Ergebnisse aufbereitet werden. Damit wird nicht nur die Compliance sichergestellt, sondern auch das Vertrauen in die neue Reporting-Welt gestärkt.
Mein finales Fazit
Das Reporting der Zukunft ist schnell, adaptiv, nutzerzentriert und vertrauenswürdig. Es verlässt die Ästhetik reiner Visualisierung und fokussiert sich stattdessen auf das Wesentliche: relevante Erkenntnisse im richtigen Moment – für die richtigen Menschen.
Nicht mehr das Erstellen schöner Dashboards steht im Vordergrund, sondern die Fähigkeit, gezielte Fragen in Echtzeit beantworten zu können – eingebettet in einen klar definierten Kontext.
Unternehmen, die heute in kontextgesteuerte Architekturen und KI-gestütztes Reporting investieren, legen das Fundament für ein neues Datenverständnis: weniger Aufwand, mehr Klarheit, bessere Entscheidungen.
Sie sichern sich nicht nur Effizienz, sondern auch Wettbewerbsvorteile in einer datengetriebenen Welt, die sich immer schneller dreht.
Teile diesen Artikel:







