
The world of data is evolving. While many companies are still consolidating their traditional data warehouses or modern data lakes, a new concept is gaining momentum: Data Mesh. This approach promises not just a new technical architecture but a fundamental shift in how organizations handle data. But what exactly is behind the hype? How has it developed historically - and can it really deliver on its promises? This article takes a closer look.
From Centralized to Decentralized: A Brief History of Data Architectures
The evolution of data architecture can be seen as a journey from centralization to decentralization. In the late 1980s, data warehouses emerged as central platforms for structured data. For the first time, they enabled the separation of operational and analytical data and still serve as the backbone of many BI systems today.
However, with the advent of big data and unstructured information, these centralized models reached their limits. From 2010 onward, data lakes entered the scene - flexible, schema-less repositories capable of storing large volumes of data cost-effectively. But these often came at the cost of governance, quality, and transparency.
To combine the best of both worlds, the data lakehouse concept emerged around 2015. It sought to combine the structure of a warehouse with the flexibility of a lake. And yet, all of these approaches were ultimately centrally managed.
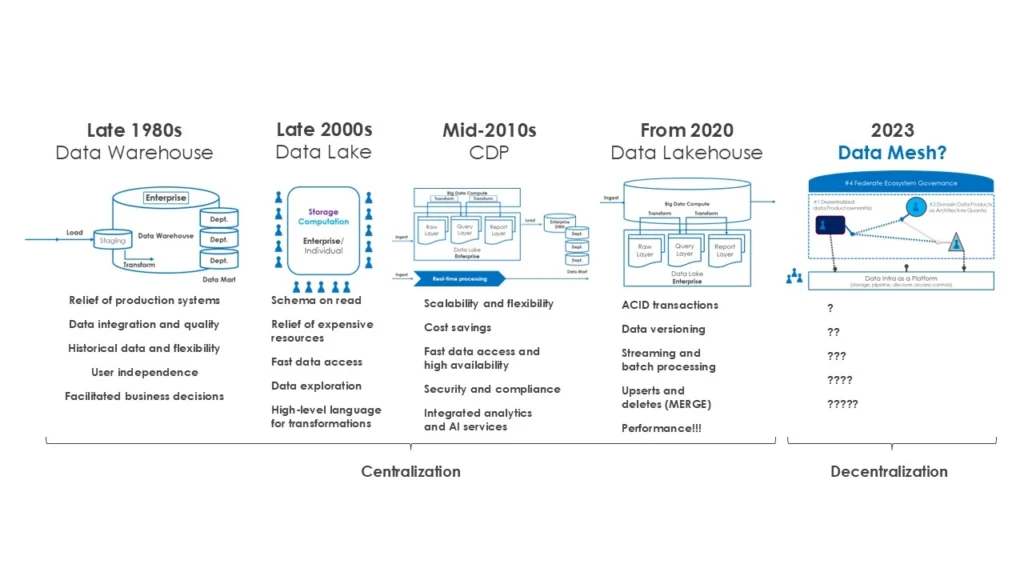
Now, Data Mesh proposes a different path. It shifts responsibility, architecture, and even the creation of data products directly into business domains - with the aim of acting faster, more scalably, and closer to business needs.
What is Data Mesh - and Why is Everyone Talking About It?
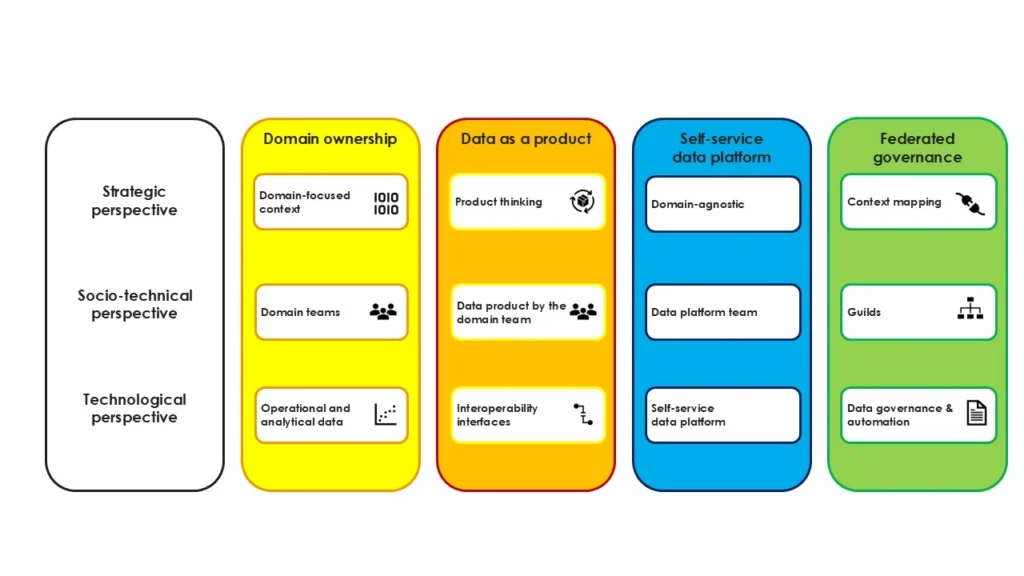
Data Mesh is not a technology or a product. Rather, it's an organizational and architectural concept based on four key principles:
- Domain Ownership: Business units - like marketing, sales, or operations - take responsibility for the data they generate.
- Data as a Product: Data is no longer seen as a byproduct but is treated as a usable product - with quality standards, SLAs, documentation, and a customer-oriented mindset.
- Self-Service Data Infrastructure: A central platform enables teams to independently publish, manage, and access data without having to wait for central IT support.
- Federated Governance: Uniform rules for data protection, quality, and interoperability are centrally defined but implemented locally - taking domain-specific needs into account.
This all sounds promising - and it is. Data Mesh aims to solve the scalability and bottleneck problems of traditional centralized architectures and helps organizations become truly data-driven.

A Paradigm Shift - with Hidden Pitfalls
As promising as Data Mesh may sound, a realistic view is crucial. One of the biggest challenges is that there is no universally accepted definition of what Data Mesh actually is. The decentralization concept is attractive, but implementing it is far from simple.
Many organizations underestimate how profound the transformation must be. It's not enough to delegate a few responsibilities to the business units. Data Mesh requires a new organizational culture - one in which data literacy, ownership, and close collaboration between IT, data teams, and business domains are essential. Without strong governance, the result can quickly be chaos: redundant data, fragmented technologies, and the rise of new silos.
And there's more: the technical foundation must also be solid. A reliable self-service platform with tools such as data catalogs, access management, monitoring, and automation is critical but also expensive and complex to maintain.
What Data Mesh Can - and Can’t - Deliver
There’s no question that Data Mesh offers great potential. When responsibility and data competence are brought into the business units, use cases can be implemented faster and more effectively. Data products are created by those who understand the context best - not by abstract central engineering teams.

However, the model is not suitable for every organization. For smaller businesses or those just beginning their data journey, implementing a full Data Mesh architecture may be overkill. In such cases, a well-designed data lakehouse or even a traditional data warehouse might be more appropriate and manageable.
Data Mesh shows its strength in large, complex organizations with multiple domains - especially where centralized platforms are no longer scalable or adaptable enough to meet the growing demand for data products.
Data Warehouse, Lakehouse, or Data Mesh? A Comparative Perspective
A structured comparison helps to put these models into perspective:
- Data Warehouse: Strong for BI and reporting, but limited in scalability and unsuitable for unstructured data.
- Data Lakehouse: Flexible, cost-efficient, and designed for both batch and streaming data - with ACID compliance.
- Data Mesh: Designed for decentralization, domain-specific responsibility, and business alignment - but comes with high organizational and technical demands.
The right choice depends on an organization’s maturity, data strategy, and company culture. There is no one-size-fits-all solution - only what fits your needs best.

Proof of Cognition: when AI agents take over the reins of blockchain
Read More →Conclusion: Between Vision and Reality
Data Mesh is not a hype - but it's also not a silver bullet. It challenges organizations to rethink their processes, responsibilities, and technologies from the ground up. Those who want to implement Data Mesh seriously must prepare for a long journey - governed by strategy, governance, platform investments, and change management.
When done right, Data Mesh can help companies become more agile, scalable, and efficient in their use of data. But without a clear plan, defined responsibilities, and the right infrastructure, the model can quickly become chaotic and counterproductive.
At the end of the day, one thing is clear:
Data Mesh is a promise - not a finished product.
And like every promise, it’s up to the organization to make it a reality.
Teile diesen Artikel:







