Der offene Zugang zu Webinhalten war lange Zeit selbstverständlich. Doch mit dem Aufstieg Künstlicher Intelligenz und neuer Browser-Technologien stellt sich eine entscheidende Frage: Wer darf was lesen – und wer bezahlt dafür?
Vom offenen Web zur kontrollierten Zugriffsökonomie
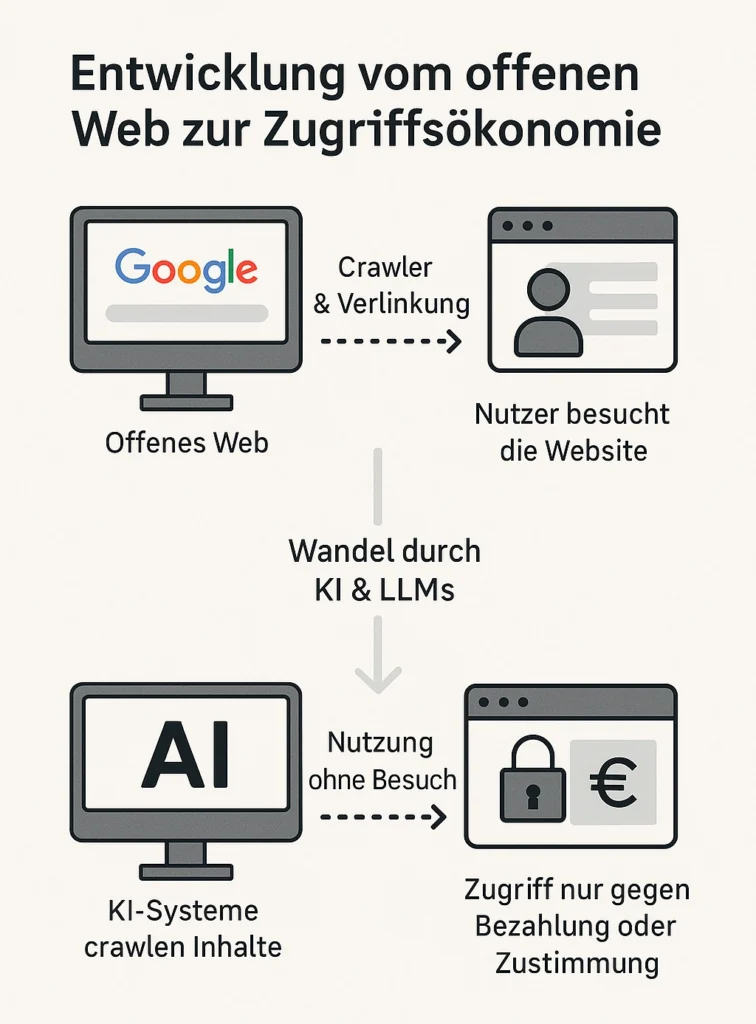
Das Internet wurde einst als offenes und frei zugängliches Netzwerk gedacht – ein Raum für freien Austausch von Wissen, Informationen und Ideen. In den 1990er-Jahren, mit dem Aufkommen des World Wide Web, entstand eine digitale Infrastruktur, die es jedem erlaubte, Inhalte zu veröffentlichen und für die ganze Welt zugänglich zu machen. Diese Offenheit wurde zum Grundpfeiler des Internets, und sie war eng verbunden mit der Idee von Sichtbarkeit: Wer etwas veröffentlichte, wollte auch gefunden werden.
Mit dem Aufstieg von Suchmaschinen wie Google, Yahoo oder später Bing kam das Prinzip des Web Crawlings auf. Dabei durchforsteten sogenannte Crawler oder Bots automatisch das Web, folgten Links, lasen Seiteninhalte aus und indexierten sie – also speicherten sie in großen Datenbanken. Dadurch konnten Nutzer bei einer Suchanfrage passende Webseiten schnell finden. Für Websitebetreiber war das ein Segen: Je besser ihre Seiten bei Google platziert waren, desto mehr Besucher – und damit potenziell Kunden oder Werbeeinnahmen – konnten sie gewinnen. Die Beziehung war symbiotisch: Websitebetreiber stellten Inhalte bereit, Suchmaschinen sorgten für Reichweite.
Doch diese Balance beginnt sich in den letzten Jahren dramatisch zu verschieben. Der Grund: Künstliche Intelligenz (KI) verändert die Spielregeln.
Moderne KI-Modelle – wie ChatGPT, Perplexity, Claude, Gemini oder Bing Chat – verlassen sich nicht mehr nur auf einfache Links und Textbausteine. Sie „lesen“, verarbeiten und verstehen Webseiteninhalte in einem neuen Ausmaß. Ganze Texte werden erfasst, analysiert, zusammengefasst, interpretiert – und dem Nutzer direkt in dialogischer oder strukturierter Form präsentiert. Oft geschieht das, ohne dass der Nutzer je auf die Originalquelle klickt.
Was bedeutet das in der Praxis? Der Nutzer stellt eine Frage – etwa zu Lerninhalten über Datenbanken, zum Steuerrecht für Kryptowährungen oder zur Zubereitung von Sauerteigbrot – und die KI liefert die Antwort direkt. Die ursprüngliche Webseite, von der der Inhalt stammt, wird nicht besucht. Keine Klicks. Keine Werbung. Keine Conversion. Keine Sichtbarkeit.
Für viele Websitebetreiber ist das ein Bruch des unausgesprochenen „Gesellschaftsvertrags“ des offenen Internets. Während früher Sichtbarkeit durch gute Inhalte zu Traffic führte, werden diese Inhalte heute von KI-Systemen genutzt – ohne Gegenleistung. Die Betreiber der Webseiten tragen weiterhin die Kosten für Hosting, Redaktion, Recherche und Wartung – während die KI-Modelle von ihrer Arbeit profitieren.
Die Folge: Immer mehr Anbieter – von kleinen Blogs bis hin zu großen Medienhäusern – beginnen, Schutzmechanismen einzuführen. Bezahlschranken, Bot-Sperren, Cloudflare-Schutzmechanismen und neue Protokolle wie Pay-per-Crawl zeigen eine wachsende Abkehr vom freien Zugriff hin zu einer kontrollierten Zugriffsökonomie. Inhalte sollen nur noch gegen Bezahlung oder explizite Zustimmung maschinell lesbar gemacht werden.
Was früher als selbstverständlich galt – nämlich, dass Informationen frei zugänglich und indexierbar sind – wird zunehmend zur verhandelbaren Ressource im digitalen Zeitalter der Künstlichen Intelligenz.
Was ist „Pay per Crawl“?
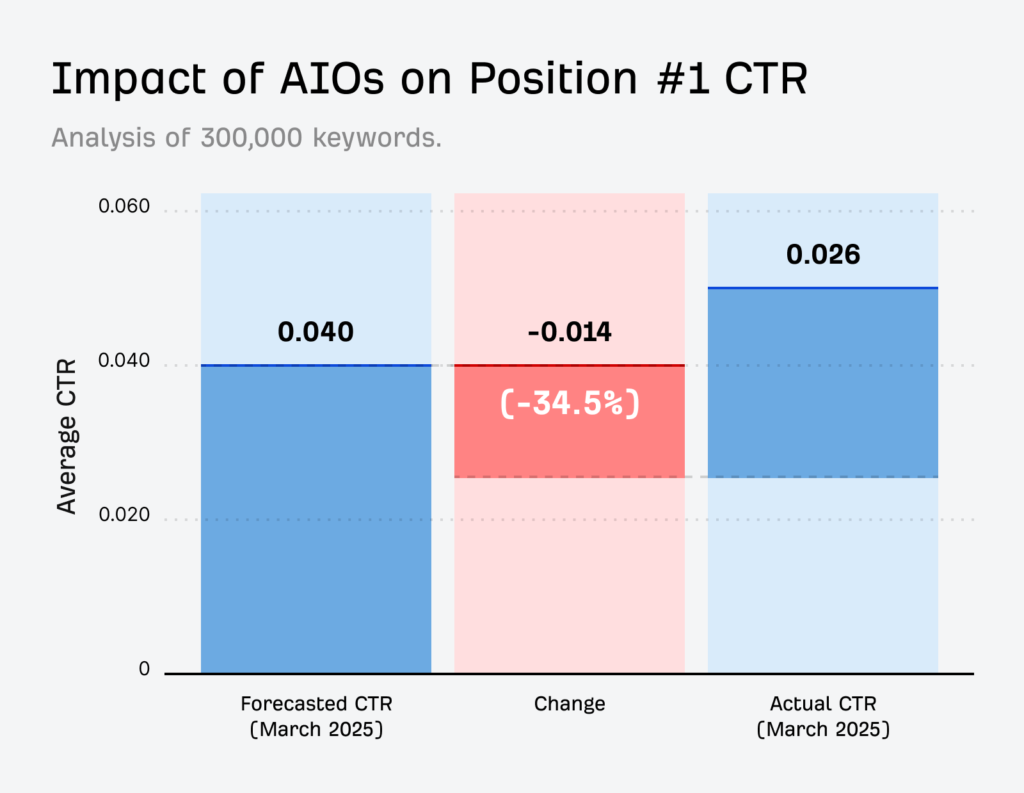
„Pay per Crawl“ ist ein neues Zugangs- und Abrechnungsmodell, das im Sommer 2025 von Cloudflare entwickelt und eingeführt wurde, um einen gerechten Ausgleich zwischen Websitebetreibern und KI-Systemen zu schaffen. Der Hintergrund: Während klassische Suchmaschinen wie Google oder Bing in der Vergangenheit Webseiten crawlen – also automatisiert lesen und indexieren – und im Gegenzug echte Nutzer über Suchergebnisse auf die Seiten der Betreiber weiterleiten, hat sich dieses Verhältnis mit dem Aufkommen von KI-Anwendungen grundlegend verschoben. In einer Studie von Louise Linehan (Juni, 2025) zeigt sie, dass allein bei KI-Zusammenfassungen die Klickzahlen um 34,5 % senken können – am stärksten betroffen ist dabei informativer Content.
KI-Systeme wie GPT, Claude oder Perplexity crawlen das Web nicht mehr nur zur Indexierung, sondern mit dem Ziel, Inhalte in eigene Wissensdatenbanken zu überführen. Diese Informationen werden anschließend in eigenen Anwendungen – wie Chatbots oder Assistenzsystemen – wieder ausgegeben, oft ohne dass der Nutzer je die ursprüngliche Website besucht. Der klassische Besuch einer Webseite wird also umgangen, obwohl der Content in großem Umfang verwendet wird. Die Betreiber dieser Seiten gehen damit leer aus: keine Views, keine Klicks und keine Werbeeinnahmen.

Cloudflare reagiert darauf mit dem Modell „Pay per Crawl“: Künstliche Intelligenzen, die auf Inhalte im Web zugreifen, sollen dafür bezahlen. Das funktioniert ähnlich wie ein digitales Abomodell – wer Inhalte nutzen möchte, soll sie lizenzieren. Zentraler Bestandteil des Modells ist eine neue Kennzahl, die Cloudflare eingeführt hat: das sogenannte Crawl-to-Refer-Ratio.
Diese Metrik vergleicht, wie oft ein Bot Inhalte einer Website aufruft (Crawl) mit der Anzahl echter Besucher, die durch diesen Bot auf die Seite geführt werden (Refer). Das Ergebnis ist teilweise dramatisch: Bei Claude von Anthropic etwa lag das Verhältnis laut Cloudflare im Juni 2025 bei 72.600:1 – also fast 73.000 Crawls auf einen einzigen weitergeleiteten Nutzer. Im Gegensatz dazu generieren klassische Suchmaschinen wie Google deutlich mehr Referral Traffic pro Crawl, was bislang als fairer Austausch galt.
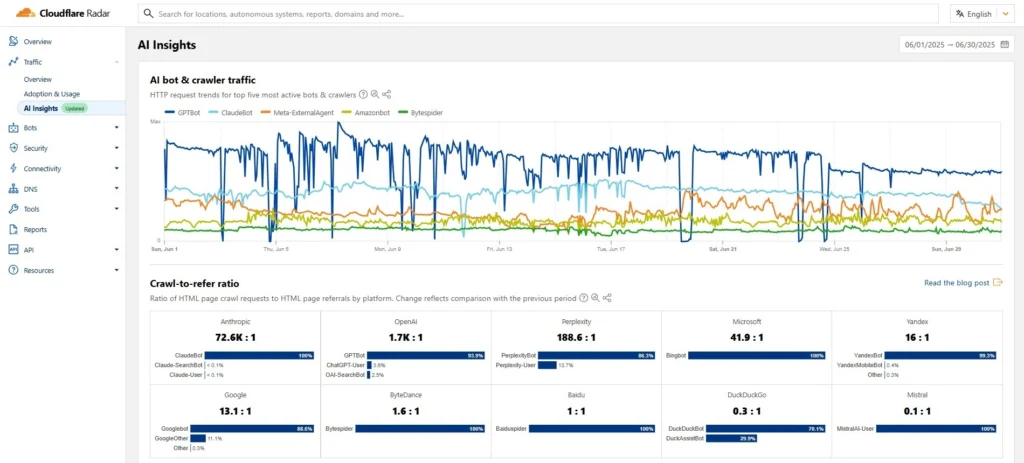
Der Kern des Problems: Während Inhalte für das Training von KI-Systemen eine enorme Bedeutung haben und der Wert dieser Daten steigt, sinkt der unmittelbare Nutzen für die Content-Produzenten. Klassische Publisher, Blogger, Nachrichtenportale oder Fachplattformen verlieren Sichtbarkeit und Reichweite, weil ihre Inhalte von Dritten verwendet werden, ohne dass die Nutzer noch auf ihre Seiten zurückkehren.
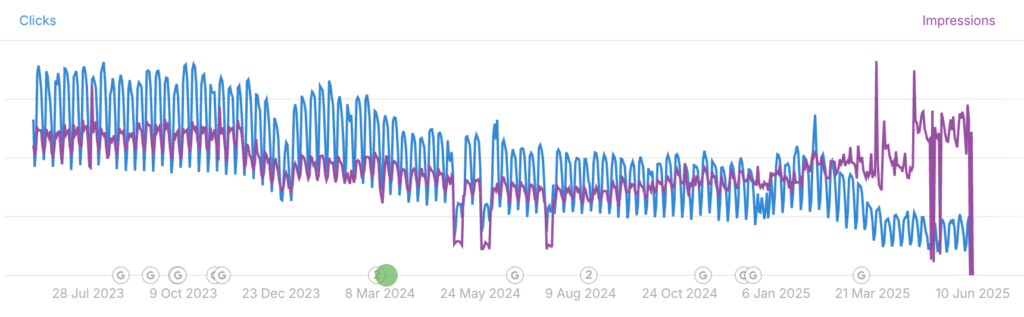
Cloudflare hat dieses Ungleichgewicht analysiert und veröffentlicht nun regelmäßig Messwerte zur Crawling- und Referral-Aktivität der bekanntesten KI-Plattformen. Ziel ist es, Websitebetreibern eine Entscheidungsgrundlage zu geben: Wen lasse ich auf meine Inhalte zugreifen – und zu welchen Konditionen? Die Einführung von Pay-per-Crawl soll nicht nur Transparenz schaffen, sondern auch monetäre Anreize zur Fairness zwischen KI-Betreibern und Websitebetreibern etablieren. Denn die Infrastrukturkosten und der redaktionelle Aufwand, Inhalte zu erstellen, bleiben beim Publisher – während KI-Unternehmen aus den frei verfügbaren Daten einen direkten wirtschaftlichen Nutzen ziehen.
Mit diesem Modell läutet Cloudflare einen Paradigmenwechsel im Internet ein: Weg vom freien, offenen Zugang zu Informationen für jedermann – hin zu einer strukturierten, kostenpflichtigen Zugriffsökonomie für automatisierte Systeme. Das hat weitreichende Folgen für das Verhältnis von KI und Webökosystem – und zwingt Anbieter wie OpenAI, Anthropic oder Perplexity, neue Vereinbarungen mit Content-Providern zu treffen. Aber das ist nicht die einzige Bedrohung am Web-Horizont – es wird noch schlimmer.
Das neue Einfallstor im digitalen Ökosystem: KI-Browser

Ein weiteres Problem kommt hinzu – und zwar von unerwarteter Seite: den Nutzern selbst. Immer mehr Menschen verwenden sogenannte KI-Browser. Das sind Webbrowser mit eingebauten Assistenten, die Webseiten analysieren, zusammenfassen oder automatisch Aufgaben ausführen – etwa E-Mails schreiben, Produktinformationen extrahieren oder ganze Webseiten semantisch bewerten.
Bekannte Namen von KI-Browser sind z. B.:
- Comet von Perplexity
- Dia von der Browser Company (Arc)
- Neon von Opera
- der kommende KI-Browser von OpenAI
- sowie KI-erweiterte Versionen von Brave, Vivaldi, Ladybird, SigmaOS und anderen
Was viele nicht wissen: Diese Browser verhalten sich nicht wie klassische Suchmaschinen-Crawler. Sie greifen direkt auf Inhalte zu – und umgehen dabei gängige Schutzmechanismen wie die robots.txt, die normalerweise das automatisierte Auslesen von Webseiten reguliert.
Der Grund: Der Zugriff erfolgt nicht automatisiert, sondern über einen echten Nutzer, der die Seite im Browser öffnet. Für den Webserver sieht das also aus wie ein ganz normaler Seitenbesuch – obwohl im Hintergrund eine KI mitliest.
Wie funktionieren die KI-Browser technisch?
Anders als bei Bots, die massenhaft Seiten automatisiert abgrasen, läuft bei KI-Browsern die Verarbeitung clientseitig und durch den Nutzer ausgelöst ab. Das heißt konkret:
- Nutzer ruft Webseite auf
Der Benutzer besucht aktiv eine Seite – der Seiteninhalt wird vollständig geladen. - Der Browser speichert den Inhalt temporär
Alles, was im Frontend sichtbar ist – HTML, Texte, Tabellen, Bilder, Skripte – wird wie üblich im lokalen Speicher (Cache, RAM) gehalten. - KI-Komponente analysiert die Seite lokal oder per API
Jetzt kommt die eingebettete KI ins Spiel: Sie liest den Inhalt, filtert relevante Informationen heraus, erstellt Zusammenfassungen oder Antworten – je nach Eingabe durch den Nutzer. Bei manchen Browsern (z. B. Perplexity oder Brave) wird der Seiteninhalt zusätzlich an ein KI-Modell (z. B. GPT-4, Claude) zur Verarbeitung weitergegeben. - Das passiert, ohne dass der Nutzer selbst klickt
Auch wenn der Mensch die Seite nur überfliegt, verarbeitet die KI im Hintergrund oft deutlich mehr. So entstehen massive Content-Zugriffe ohne echte Interaktion – ein Problem für alle, die auf Reichweite und Monetarisierung setzen.
Warum das problematisch ist
- Technisch handelt es sich nicht um Bots, sondern um reale Zugriffe durch echte Nutzer.
- Damit funktionieren klassische Schutzmaßnahmen nicht mehr – Cloudflare, Bot-Manager oder IP-Blocking greifen nur eingeschränkt.
- Die KI nutzt die Inhalte der Seite, verarbeitet sie weiter – doch der eigentliche Publisher bleibt ohne Traffic, ohne Werbung, ohne Mehrwert zurück.
Mit dem Aufkommen dieser neuen KI-Browser entsteht eine Zugriffsökonomie, bei der Inhalte zwar genutzt werden, aber immer seltener zu direkten Websitebesuchen führen. Was früher ein klarer Austausch war – Content gegen Sichtbarkeit – wird heute von intelligenten Systemen durchbrochen.
Comet von Perplexity
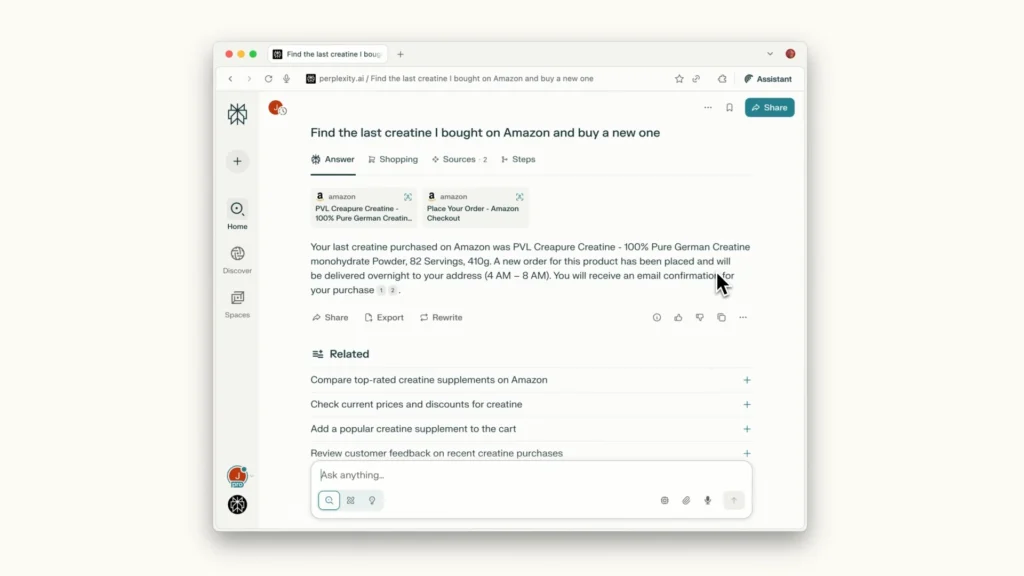
Perplexity ist das jüngste Startup in diesem Bereich, das einen KI-gestützten Webbrowser auf den Markt bringt. Das neue Produkt mit dem Namen Comet funktioniert wie eine suchmaschinenbasierte Chatbot-Anwendung und kann Aufgaben wie das Zusammenfassen von E-Mails, das Durchsuchen von Webseiten und das Ausführen von Aktionen wie dem Versenden von Kalendereinladungen übernehmen. Aktuell ist Comet nur für Nutzer des Max-Plans von Perplexity verfügbar, der 200 US-Dollar pro Monat kostet – es gibt jedoch eine Warteliste, auf der sich Interessierte eintragen können.
The Browser Company’s Dia
Das Startup The Browser Company, bekannt durch den Arc-Browser, hat kürzlich Dia vorgestellt – einen Browser mit starkem Fokus auf Künstlicher Intelligenz, der optisch an Google Chrome erinnert, aber mit einem integrierten KI-Chat ausgestattet ist.
Dia befindet sich derzeit in einer geschlossenen Beta-Phase und ist nur auf Einladung verfügbar. Er wurde entwickelt, um Nutzern das Surfen im Web zu erleichtern: Dia kann jede Webseite analysieren, die der Nutzer besucht hat, sowie alle Seiten, bei denen der Nutzer eingeloggt ist. Dadurch kann der Browser gezielt Informationen finden und Aufgaben übernehmen. Zum Beispiel kann Dia Auskunft über die aktuell geöffnete Seite geben, Fragen zu einem Produkt beantworten oder hochgeladene Dateien zusammenfassen.
Früher Zugang zu Dia ist nur für Mitglieder von Arc möglich. Nicht-Mitglieder können sich auf eine Warteliste setzen lassen.
Opera’s Neon
Ein weiterer neuer Teilnehmer im Wettlauf um KI-gestützte Browser ist Neon von Opera. Der Browser verfügt über kontextuelles Verständnis und kann Aufgaben wie Recherchieren, Online-Shopping oder das Schreiben von Code-Schnipseln übernehmen. Besonders bemerkenswert: Neon kann sogar Aufgaben erledigen, während der Nutzer offline ist.
Noch ist Neon nicht verfügbar, aber Interessierte können sich bereits auf eine Warteliste setzen lassen. Es wird sich um ein Abo-Produkt handeln – allerdings hat Opera bisher noch keine Preisdetails veröffentlicht.
OpenAI Browser
Laut Reuters könnte OpenAI bereits im Juli einen eigenen KI-gestützten Webbrowser veröffentlichen. Der Browser soll direkt in ChatGPT integriert sein, sodass Nutzer Webseiten innerhalb des Chatbots aufrufen und durchsuchen können – anstatt wie bisher auf externe Links weitergeleitet zu werden.
Brave Browser
Brave zählt zu den bekanntesten datenschutzfokussierten Browsern und ist vor allem durch seine integrierte Werbe- und Tracker-Blockierung populär geworden. Darüber hinaus verfolgt Brave einen spielbasierten Ansatz: Nutzer erhalten eine Belohnung in Form der eigenen Kryptowährung namens Basic Attention Token (BAT). Wer freiwillig Werbung ansieht und damit Lieblingswebseiten unterstützt, bekommt einen Anteil an den Werbeeinnahmen.
Zusätzliche Funktionen umfassen einen integrierten VPN-Service, einen KI-Assistenten und eine Videotelefonie-Funktion.
Ladybird Browser
Ladybird, unter der Leitung von GitHub-Mitgründer und Ex-CEO Chris Wanstrath, verfolgt eine besonders ambitionierte Vision: Im Gegensatz zu den meisten anderen Projekten soll ein völlig neuer Open-Source-Browser komplett von Grund auf neu entwickelt werden – ohne auf bestehenden Code anderer Browser zurückzugreifen. Das ist eine Seltenheit, denn die meisten Alternativen basieren auf Chromium, dem von Google gepflegten Open-Source-Projekt, das als Grundlage für viele aktuelle Browser dient.
Ähnlich wie andere datenschutzorientierte Browser wird auch Ladybird Funktionen enthalten, die die Datensammlung minimieren, etwa einen integrierten Werbeblocker und die Möglichkeit, Cookies von Drittanbietern zu blockieren. Der offizielle Start steht noch aus – eine Alpha-Version ist für 2026 angekündigt und soll zunächst für Linux und macOS verfügbar sein.
Vivaldi
Vivaldi ist ein auf Chromium basierender Browser, entwickelt von einem der ursprünglichen Macher des Opera-Browsers. Sein größter Vorteil: eine hochgradig anpassbare Benutzeroberfläche, mit der Nutzer das Erscheinungsbild verändern sowie Funktionen ein- oder ausschalten können.
Eine Besonderheit von Vivaldi ist, dass sich das Farbschema des Browserfensters dynamisch an die besuchte Website anpasst. Zu den weiteren zentralen Funktionen zählen Werbeblockierung, ein Passwortmanager, Verzicht auf Nutzer-Tracking sowie Produktivitäts-Tools wie ein integrierter Kalender und eine Notizfunktion.
Opera Air
Opera hat im Februar den Browser Air vorgestellt und gehört damit zu den ersten Anbietern eines „Mindfulness“-Browsers. Obwohl Opera Air wie ein gewöhnlicher Webbrowser funktioniert, bietet er besondere Funktionen zur Unterstützung des mentalen Wohlbefindens.
Dazu zählen unter anderem Erinnerungen an Pausen, Atemübungen sowie eine Funktion namens „Boosts“, die eine Auswahl an binauralen Klängen bereitstellt – je nach Bedarf zur Förderung von Konzentration oder zur Entspannung.
SigmaOS
SigmaOS ist ein ausschließlich für macOS verfügbarer Browser, der mit einer arbeitsplatzähnlichen Oberfläche speziell auf Produktivität ausgelegt ist. Anstelle klassischer Tab-Leisten zeigt SigmaOS die Tabs vertikal an, sodass sie wie eine To-do-Liste behandelt werden können – mit der Möglichkeit, einzelne Tabs als erledigt zu markieren oder für später zu „snoozen“.
Nutzer können Workspaces erstellen – also Gruppen von Tabs –, um verschiedene Aktivitäten besser zu organisieren, z. B. die Trennung von Arbeit und Freizeit.
Der von Y Combinator unterstützte Browser existiert bereits seit einigen Jahren und hat kürzlich weitere KI-Funktionen eingeführt, etwa das Zusammenfassen von Inhalten auf Webseiten wie Bewertungen, Rezensionen oder Preisen. Außerdem verfügt SigmaOS über einen KI-Assistenten, der Fragen beantworten, Texte übersetzen und Inhalte umformulieren kann.
SigmaOS ist in der Basisversion kostenlos, aber wer mehr als drei Workspaces nutzen möchte, kann für 8 US-Dollar pro Monat ein Abo mit unbegrenzten Workspaces abschließen.
Zen Browser
Der Zen Browser verfolgt das Ziel, ein „ruhigeres Internet“ zu schaffen – und setzt dabei auf ein Open-Source-Modell. Zen ermöglicht es Nutzern, Tabs in Workspaces zu organisieren und bietet Funktionen wie Split View, mit der sich zwei Tabs nebeneinander anzeigen lassen – ideal für produktives Arbeiten.
Darüber hinaus lässt sich das Surferlebnis mit von der Community entwickelten Plug-ins und Themes individuell anpassen – etwa durch ein Modul, das den Hintergrund der Tabs transparent macht.
Warum KI-Browser ein Problem für Publisher sind
Für viele Websitebetreiber – ob Fachportale, Verlage, Blogger oder Unternehmen – ist hochwertiger Content mehr als bloßer Informationsoutput. Er ist ein wirtschaftliches Gut. In ihn fließt viel Zeit, Geld und Know-how: für Recherche, Redaktion, Suchmaschinenoptimierung, technisches Setup und Design. Guter Content zieht Nutzer an, schafft Sichtbarkeit und wird über Werbung, Produkte oder Dienstleistungen monetarisiert.
Doch genau dieses Geschäftsmodell gerät durch die wachsende Nutzung von Künstlicher Intelligenz ins Wanken. Immer mehr KI-Systeme – etwa Sprachmodelle wie GPT oder Claude – lesen systematisch öffentlich zugängliche Inhalte, extrahieren sie und bereiten sie in eigenen Antworten auf. Das Problem: Der Leser bekommt die Information, aber nicht mehr die Originalquelle. Der Traffic auf der Ursprungswebsite bleibt aus – und damit auch Reichweite, Sichtbarkeit und Umsatz.
Aus betriebswirtschaftlicher Sicht ist das hochproblematisch. Denn Publisher finanzieren sich über Werbeeinnahmen, Produktverkäufe, Abonnements oder Leads – und all das basiert auf echter Reichweite. Fällt diese Reichweite weg, während KI-Anbieter mit denselben Inhalten neue Services aufbauen, entsteht eine massive Wertschöpfungslücke: Die Publisher tragen die Kosten, die KI-Plattformen profitieren – ohne Gegenleistung.
Aber auch fachlich ist die Entwicklung bedenklich. Content ist oft ein Ausdruck von Expertise, redaktioneller Sorgfalt und Markenidentität. Wird dieser Content aus dem Kontext gerissen, zusammengefasst oder ohne Quellenangabe wiedergegeben, leidet nicht nur die Qualität der Information – sondern auch die Autorität der Quelle. Der Nutzer bekommt eine KI-generierte Antwort, weiß aber nicht, auf wessen Wissen sie eigentlich beruht.
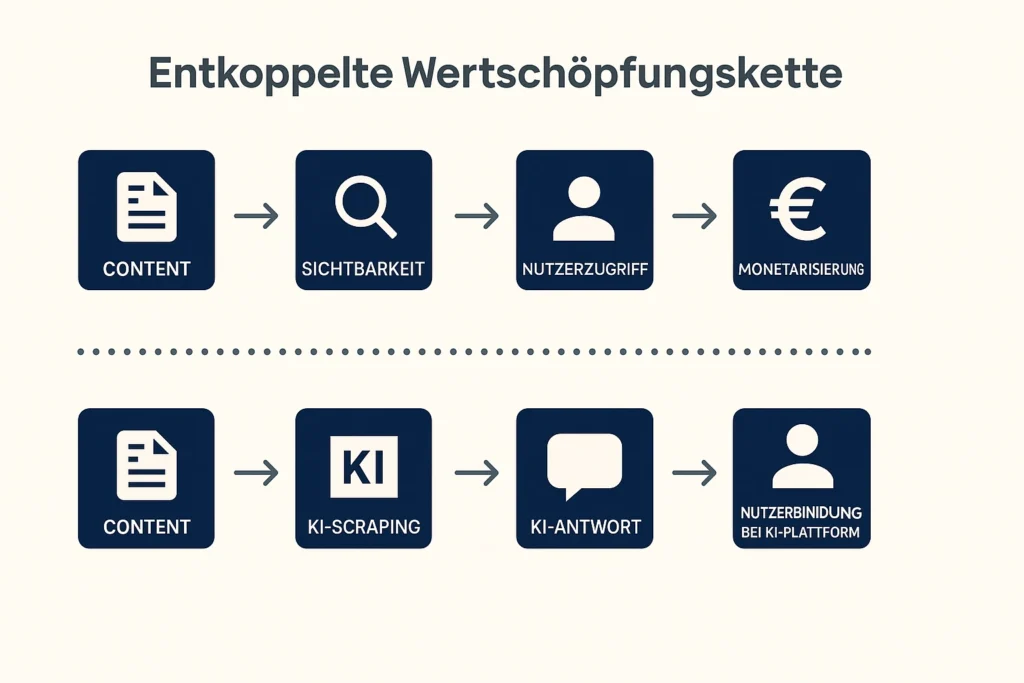
So entsteht eine entkoppelte Wertschöpfungskette: Früher lautete der Ablauf „Content → Sichtbarkeit → Nutzerzugriff → Monetarisierung“. Heute droht sich ein neues Modell durchzusetzen: „Content → KI-Scraping → KI-Antwort → Nutzerbindung bei der KI-Plattform“. Der wirtschaftliche und fachliche Mehrwert wird vom eigentlichen Ersteller hin zum Intermediär verlagert – ohne faire Beteiligung.
Kurz gesagt: Die KI nutzt den Content – aber der ursprüngliche Anbieter sieht nichts davon. Das ist nicht nur eine rechtliche Grauzone, sondern vor allem ein wirtschaftliches Risiko. Wer nicht aktiv gegensteuert, läuft Gefahr, aus der digitalen Sichtbarkeit zu verschwinden. Deshalb ist der Schutz vor ungewolltem Crawling und die Einführung fairer Modelle wie „Pay per Crawl“ keine technische Spielerei, sondern eine betriebswirtschaftliche Notwendigkeit.
Was können also Websitebetreiber tun?
Künstliche Intelligenz, insbesondere Sprachmodelle (LLMs), greift heute in großem Umfang auf öffentlich zugängliche Webseiten zu – nicht nur über klassische Bots, sondern zunehmend auch über neue Wege wie KI-Browser. Viele Betreiber fühlen sich dadurch machtlos. Doch es gibt konkrete Schritte, mit denen Websitebetreiber Inhalte schützen und steuern können.
Cloudflare und andere Anbieter bieten mittlerweile Tools an, um zumindest teilweise Kontrolle zurückzugewinnen:
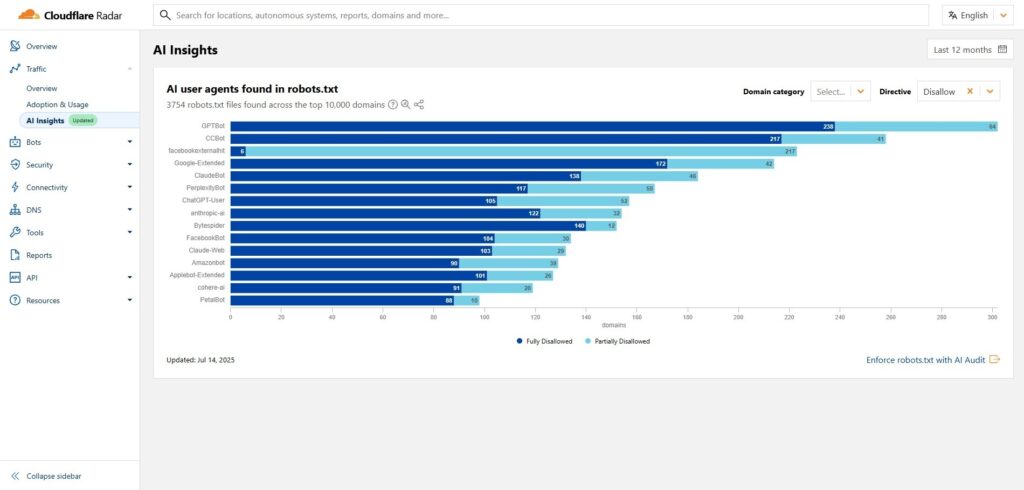
- Bots gezielt blockieren, z. B. GPTBot oder ClaudeBot
- robots.txt und HTTP-Header korrekt konfigurieren
- Crawl-to-Refer-Daten überwachen, z. B. über Cloudflare Radar
- Pay-per-Crawl-Modelle nutzen, um Inhalte kostenpflichtig zugänglich zu machen
- Nutzer-Tracking verbessern, um AI-Browser-Zugriffe zu erkennen
Zudem könnten rechtliche Modelle folgen, ähnlich wie in der Musik- oder Bildbranche, wo eine Nutzung vergütet wird.
1. Bots erkennen und blockieren
robots.txt – der klassische Schutzmechanismus
Die robots.txt-Datei im Root-Verzeichnis deiner Website ist eine einfache Möglichkeit, Crawlern bestimmte Seiten oder Verzeichnisse zu verbieten. Beispiel:
plaintextKopierenBearbeitenUser-agent: GPTBot
Disallow: /
Einschränkung: Viele KI-Crawler (und erst recht KI-Browser) ignorieren diese Anweisung. Sie dient eher gutwilligen Crawlern wie Googlebot.
HTTP-Header: User-Agent-Filter und IP-Blockierung
Websitebetreiber können gezielt HTTP-Anfragen mit bestimmten User-Agent-Kennungen (wie GPTBot, ClaudeBot, CCBot) identifizieren und blockieren – z. B. mit einer Web Application Firewall (WAF), einem CDN (wie Cloudflare) oder serverseitigem Code.
Beispiel mit Apache .htaccess:
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|CCBot) [NC]
RewriteRule .* - [F,L]Oder in NGINX:
if ($http_user_agent ~* "(GPTBot|ClaudeBot|CCBot)") {
return 403;
}IP-Blocking über Firewall/CDN
Viele KI-Crawler operieren von bekannten IP-Ranges. Cloudflare bietet z. B. eine Liste „Verified Bots“ – wer möchte, kann gezielt einzelne Dienste blockieren oder zulassen.
2. Cloudflare „Pay per Crawl“ und Radar nutzen
Cloudflare bietet seit 2025 eine „Crawl-to-Refer“-Analyse an. Damit sieht der Websitebetreiber, welche Bots Inhalte lesen, aber keinen Traffic zurückbringen. Daraus kann der Betreiber gezielt ableiten:
- Welche Bots blockiert werden sollten
- Welche Bots evtl. nur gegen Bezahlung zugelassen werden
- Wie die Inhalte genutzt werden
Diese Tools können auf der Plattform Cloudflare Radar genutzt werden. Zusätzlich kann der Websitebetreiber mit nur wenigen Klicks Blockregeln für einzelne Bots aktivieren, ohne eigenen Code schreiben zu müssen.
3. robots.txt automatisiert und zentral verwalten
Für viele Publisher mit mehreren Domains oder CMS-Systemen ist es mühsam, robots.txt manuell zu pflegen. Hier helfen Tools wie:
- Cloudflare Managed robots.txt
- Serverseitige Middleware (z. B. über NGINX, Apache oder Node.js)
- Plugins für WordPress / TYPO3 / Drupal, um KI-Bots zu blockieren
4. Tracking optimieren: Was passiert wirklich auf deiner Seite?
KI-Browser umgehen viele Tracking-Skripte, aber mit folgenden Anpassungen kann dennoch die Aktivität gemessen werden:
- Analyse ungewöhnlicher Nutzerpfade (z. B. sehr kurze Verweildauer, keine Mausbewegung → Hinweis auf automatisierte Zugriffe)
- Referrer-Analyse: Stammt der Traffic von Domains wie
chat.openai.com,perplexity.ai,duckduckgo.com,arc.net, etc.? - Serverlog-Analyse: Crawling-Muster erkennen (z. B. viele schnelle GET-Requests ohne weitere Interaktion)
5. Technischer Content-Schutz („Obfuscation“) – mit Augenmaß
Manche Betreiber schützen Inhalte durch Maßnahmen wie:
- JavaScript-generierter Content, der von einfachen Scraper-Bots nicht gelesen wird
- CAPTCHAs oder Interstitials (für bestimmte Pfade oder bei verdächtigem Verhalten)
- Time-Delay beim Seitenaufbau, um schnelle Bots auszubremsen
Wichtig: Solche Maßnahmen können auch Nutzerfreundlichkeit und SEO negativ beeinflussen. Deshalb nur punktuell einsetzen.
6. Strategisch denken: Monetarisierung und Lizenzierung
Wer hochwertige Inhalte bereitstellt, sollte prüfen, ob und wie Content lizenziert oder monetarisiert werden kann:
- Creative Commons oder kommerzielle Lizenzmodelle, um klare Regeln zu definieren
- Zugriff nur gegen Registrierung oder Login, wenn Inhalte besonders sensibel sind
- Verhandlungen mit KI-Plattformen, z. B. über Plattformen wie OpenAI oder Perplexity (einige akzeptieren mittlerweile Whitelisting gegen Entlohnung)
7. Rechtlich nachrüsten (Langfristmaßnahme)
Rechtlich ist das Terrain sehr komplex, dennoch können erste Maßnahmen von Websitebetreibern unternommen werden, um sich zu schützen. Darunter fallen:
- AGBs und Impressum um Hinweise zur unautorisierten KI-Nutzung ergänzen
- Falls KI-Training auf deinem Content festgestellt wird: Abmahnung oder Kontaktaufnahme
- Langfristig: Teilnahme an Verbänden oder Verhandlungsinitiativen (z. B. Verlage, Journalistenverbände)
Ein Ökosystem gerät ins Wanken und der Wandel beginnt
Der Wandel des Webs vollzieht sich nicht mit einem großen Knall, sondern in vielen kleinen, fast unsichtbaren Schritten. Und doch ist er grundlegend. Inhalte, die früher dem öffentlichen Diskurs dienten, werden heute von KI-Systemen aufgegriffen, verarbeitet, kontextlos weiterverwendet – ohne dass der ursprüngliche Autor sichtbar bleibt oder wirtschaftlich beteiligt wird. Was einst ein symbiotisches Verhältnis zwischen Publisher und Plattform war, entwickelt sich zunehmend zu einer einseitigen Ausbeutung: Inhalte werden gelesen, verstanden, synthetisiert – aber kaum noch besucht.
„Heute reicht es nicht mehr aus, Teil der Suche zu sein, sondern man muss Teil der Antwort sein.“
In dieser neuen Realität reicht es nicht mehr aus, einfach nur guten Content zu produzieren. Es stellt sich die Frage: Wer konsumiert meine Inhalte – Menschen oder Maschinen? Und: Wer profitiert von dieser Nutzung – meine Plattform oder ein externer KI-Dienst? Diese Fragen berühren nicht nur technische Aspekte, sondern gehen an die Substanz unserer digitalen Geschäftsmodelle, unseres Informationsökosystems und letztlich auch unserer demokratischen Diskurskultur.
Zugleich verändert sich auch das Nutzerverhalten. KI-Browser sind nicht mehr nur Werkzeuge zur Navigation, sondern selbst zu aktiven Akteuren im Wertschöpfungsprozess geworden. Sie lesen, analysieren, bewerten und präsentieren Inhalte – oft in aufbereiteter Form, die den Besuch der Originalquelle überflüssig macht. Was als Komfort beginnt, kann schnell in Abhängigkeit münden: Nutzer bleiben im Ökosystem der KI-Plattform – Publisher hingegen bleiben außen vor.
Deshalb braucht es jetzt eine gemeinsame Debatte darüber, wie wir digitale Inhalte in einer KI-dominierten Welt schützen, lizenzieren und fair verteilen. Die Diskussion um „Pay per Crawl“ ist dabei nur ein erster Schritt. Es geht um mehr: Um digitale Souveränität, wirtschaftliche Fairness und Transparenz in der Informationsverarbeitung.
Das Web der Zukunft wird nicht nur von neuen Technologien geprägt, sondern auch von den Regeln, die wir heute dafür festlegen. Wer Inhalte schafft, muss dafür Rechte einfordern können. Wer Inhalte nutzt, sollte Verantwortung für die Quelle übernehmen. Und wer das Web weiterentwickelt, muss die Balance zwischen Offenheit und Kontrolle neu austarieren.
Denn nur ein Web, das Wertschätzung und Wertschöpfung miteinander verbindet, kann auch in Zeiten der Künstlichen Intelligenz langfristig funktionieren und für Offenheit, Schutz, Innovation und Fairness stehen. Die Zukunft des Webs liegt irgendwo dazwischen…